Paying for AI tools your team uses for 10% of what they cost?
Built a GPT wrapper but getting generic outputs that don't fit your product?
Generative AI Development Company
RaftLabs is a generative AI development company founded in 2019. We have shipped 100+ AI products for clients including Vodafone, Cisco, T-Mobile, Energia, and Nike. For companies your size, we deliver the same quality — in 12 weeks, at a fixed price. Most engagements run $50K–$150K. You know the cost before we write a line of code. Most businesses have bought AI tools. Few have shipped AI that their users actually trust. Off-the-shelf models give you average output — trained on average data, built for average use cases. If your product needs to generate content, process documents, handle customer queries, or automate workflows using your domain knowledge, you need custom development. We build generative AI software: LLM-powered applications, RAG pipelines, fine-tuned models, AI agents, and content automation systems. Built around your data, your workflows, and your accuracy requirements — not a generic template.
Custom LLM apps, RAG pipelines, and AI agents — not GPT wrappers
Working prototype in 2–4 weeks before full commitment
Fixed project cost — you know the price before we start
4.9/5 on Clutch — 100+ AI products shipped since 2019
The gap between AI tools and AI products
Most companies have tried AI tools. Few have shipped AI products that users trust.
The gap is this: a generic LLM gives you plausible-sounding output. But your users need accurate output — output that reflects your domain, your data, and your quality bar. A healthcare platform cannot publish clinical summaries that are plausible but wrong. A legal tech product cannot generate contract clauses that sound right but miss jurisdiction-specific requirements.
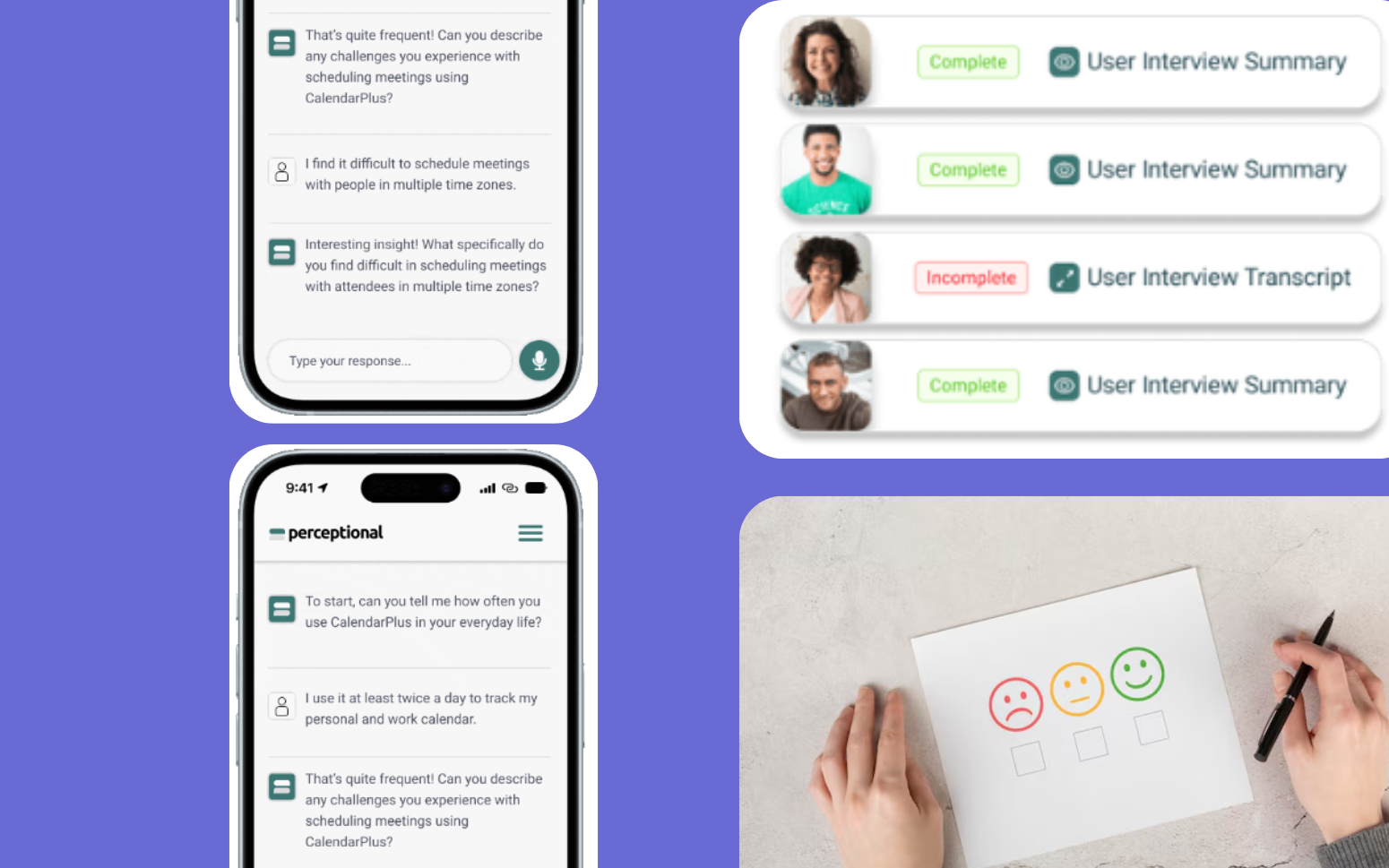
The solution is building AI software grounded in your data, constrained to your domain, and validated against your accuracy standards. That is not a tool integration — it is a product engineering problem. RaftLabs has shipped 25+ generative AI products across healthcare, logistics, media, and professional services — from Perceptional's conversational research AI (4x deeper insights, 48-hour time to findings) to PSi's real-time voice decision platform (300+ concurrent users, 98% cost reduction vs. traditional telephony).
What we build
Custom LLM applications
Full-stack applications with a language model at the core. Chatbots trained on your knowledge base, AI copilots for internal teams, and document assistants that understand your business context. We build the application layer, the retrieval pipeline, and the user interface — not just the LLM integration.
RAG-powered document intelligence
Retrieval-augmented generation systems that ground your LLM in your actual data — product documentation, support tickets, legal contracts, medical records. The model answers from your knowledge base, with citations, rather than hallucinating from general training data. See also: RAG development.
Conversational AI and chatbots
Conversational interfaces trained on your knowledge base and tuned to your brand voice. Customer-facing support agents, internal HR and IT assistants, and domain-specific Q&A systems. Built with guardrails, fallback handling, and human escalation paths. See also: AI chatbot development.
AI agents and workflow automation
Autonomous agents that execute multi-step tasks — researching, drafting, deciding, and taking action — across your business workflows. Connected to your CRM, databases, APIs, and communication tools. See also: AI agent development.
Content and code generation
Automated pipelines that generate first drafts, summarise documents, extract structured data, and produce formatted output from unstructured input. Used by marketing teams to scale content, operations teams to process documents, and product teams to automate reporting and code review.
Multimodal and vision AI
Custom pipelines for generating, editing, and processing images and documents. Product image generation, document understanding from scanned files, visual data extraction, and automated media processing for content-heavy operations.
What does your AI product actually need to do?
Tell us the business problem. We'll tell you which AI approach fits it and what it costs to build.
Three-year average engagement. Founders and operators describing the work in their own words. No marketing varnish.
Amer Abu Khajil
Founder, Peak Studios & Perceptional
Canada
“
“I found RaftLabs to be the perfect partner for Perceptional, with their expertise in helping startup founders build MVPs, a free consultation, a prototype that matched my vision, and their unwavering support.”
Generative AI applies differently by sector. These are the use cases where we have seen measurable ROI.
Healthcare and life sciences
Clinical documentation takes time that clinicians should spend on patients. A model that listens to a patient encounter, structures the transcript into a SOAP note, and pre-populates EHR fields saves 8–12 minutes per patient. At 20 patients a day, that is 160–240 minutes back per clinician.
Remote patient monitoring generates large volumes of time-series data. Generative AI can summarise trends for clinicians, flagging patients who need attention without requiring a human to read every data point. We build every healthcare AI product with HIPAA compliance built in — not added on.
Fintech and banking
Loan underwriting narratives, compliance reports, customer communication at scale — these are high-volume text generation tasks where generative AI cuts processing time significantly. One client reduced underwriting report generation from 4 hours to 15 minutes by combining structured data extraction with LLM-generated narrative sections.
Fraud detection explanation generation — why a transaction was flagged, in plain language for the customer service team — is another use case we have shipped.
Manufacturing and logistics
Quality inspection reports that previously took engineers 45 minutes can be generated in under 2 minutes when a vision model processes production line images and a language model drafts the report from a structured template.
Document extraction pipelines that process bills of lading, customs declarations, and freight invoices — pulling structured data from inconsistent formats and routing it into TMS and ERP systems — reduce manual data entry by 80–90% on the workflows we have automated.
Defense and government
Document analysis, report summarisation, and knowledge management at scale — areas where large document volumes and strict compliance requirements make manual processing unsustainable. We work with defense-adjacent clients including Lockheed Martin. We understand export control, data residency, and security classification requirements.
How we deliver: the 12-week model
How we build generative AI products
We start by understanding the problem — not the technology. What output does your user need? What data does the AI need access to? What does accuracy look like for your use case? This shapes model selection, retrieval architecture, and validation approach.
Use case definition and accuracy requirements
Data audit — what you have and what is needed
Model and architecture selection (RAG vs. fine-tuning vs. base model)
Fixed-cost quote with milestone delivery dates
Before full development, we build a working prototype that demonstrates the core AI capability. You can test it against real inputs, measure output quality, and give feedback before committing to the full build. This is the lowest-risk way to validate an AI approach.
Working AI prototype with core functionality
Accuracy baseline against your test cases
Feedback session and scope confirmation
We prepare your training data, design the retrieval pipeline, and fine-tune or configure the model. For RAG systems, this includes chunking strategy, embedding selection, and retrieval optimisation. For fine-tuned models, this includes dataset curation, training runs, and evaluation.
Data cleaning, chunking, and embedding
Retrieval pipeline design and optimisation
Model fine-tuning or prompt system design
Accuracy evaluation against held-out test set
We build the full application — the interface, the backend, the integrations — and connect it to your existing systems. The AI layer is one part of a complete product: authenticated, logged, monitored, and maintainable.
Full-stack application development
API integrations with your existing tools
Authentication, logging, and audit trail
Performance and load testing
We deploy to production, document the system, and hand over the codebase, infrastructure, and model configuration. You own everything and can run it without us.
Production deployment and monitoring setup
Codebase and system documentation
Infrastructure and credentials handover
Optional ongoing support retainer
Generative AI development cost: what to expect
Generative AI development costs are driven by team size, project complexity, and build length. Here is how common project types map to realistic budgets:
These are development costs. Model API costs at runtime sit on top — typically $0.001–$0.03 per 1,000 tokens depending on the model. At average usage volumes, this translates to pennies per user interaction. For high-volume applications, self-hosted Llama 3 starts making financial sense.
What pushes cost up: messy data (scanned PDFs, inconsistent formats add 20–40% to RAG pipeline timelines), compliance requirements (HIPAA, SOC 2, GDPR add architecture and audit overhead), and legacy system integration.
What keeps cost down: clear success criteria from day one, clean and accessible training data, a narrow initial scope, and using managed AI services (OpenAI, Anthropic, Google) rather than self-hosted infrastructure in early stages.
We give fixed-fee estimates for well-scoped projects.
Which model fits your use case
The model you pick affects cost, performance, latency, data privacy, and what you can fine-tune.
Long document analysis, nuanced instruction following
200K tokens
AWS Bedrock
Medium
Gemini 1.5 Pro
Multimodal (text + image + video + audio)
1M tokens
Google Cloud (HIPAA compliant)
Medium
Llama 3 (70B)
On-premise deployment, full data ownership
128K tokens
Self-hosted — full privacy
Low (infra cost only)
Mistral 7B / 8x7B
Lightweight tasks, fast inference, fine-tuning
32K tokens
Self-hosted
Very low
If your data cannot leave your servers — healthcare PHI, financial records under specific compliance requirements — start with Llama 3 or Mistral on self-hosted infrastructure, or use Azure OpenAI or AWS Bedrock for the managed privacy option.
If you need best-in-class output quality and your volume is under 10 million tokens per month, GPT-4o is usually the right call. At high volume, the cost math shifts toward fine-tuned smaller models.
If your use case involves very long documents (100+ pages), Claude 3.5 with its 200K context window avoids the chunking complexity that RAG introduces.
We are not locked into any vendor. We pick what works for your problem.
Generative AI development vs. AI integration: which do you need?
Generative AI development means building a new AI product from scratch — designing the architecture, preparing the data pipeline, and engineering the user-facing product. You start with a problem and build the AI system to solve it.
Generative AI integration means adding AI capability to software you already have — connecting an API, adding a model endpoint, building an AI feature into an existing product. You start with working software and add AI to it.
Most buyers need one of the two. If you have no existing product and need to build AI from the ground up, you need development. If you have working software and want to add AI features, you need integration. If you are unsure, tell us what you have and what you need — we will tell you which fits.
Related services
AI Agent Development — Autonomous agents that execute multi-step tasks across your workflows
RAG Development — Retrieval-augmented generation systems grounded in your data
Build generative AI that your users can actually trust.
Tell us the problem. We'll design the AI system and give you a fixed cost.
Proof of Concept: Working prototype in 2–4 weeks.
Zero-Obligation: Walk away in 14 days if unsatisfied.
Milestone Pricing: Pay as you go, no surprises.
Frequently Asked Questions
We build software that uses generative AI models to produce useful output: custom chatbots trained on your knowledge base, document automation tools that draft contracts or reports, AI copilots for internal workflows, content generation pipelines, code generation assistants, and fine-tuned models that understand your industry's language. We build the full product — not just the API connection.
Starter (single AI feature or chatbot): $40K–$80K, 6–8 weeks. Standard (multi-feature AI product): $80K–$150K, 10–12 weeks. Advanced (custom LLM fine-tuning + enterprise deployment): $150K–$300K, 14–20 weeks. Most mid-market projects land in the $50K–$150K range. We give you a fixed-fee quote before starting.
A working prototype takes 2–4 weeks. A production-ready AI product takes 8–14 weeks. Most projects: 12 weeks from kickoff to deployment. Timeline depends on data complexity, integration requirements, and whether fine-tuning is needed. We scope every project before quoting, so you know exactly what you're getting and when.
We work with OpenAI (GPT-4, GPT-4o), Anthropic (Claude 3.5), Google (Gemini 1.5 Pro), Meta (Llama 3), and Mistral. We select the right model based on your cost, latency, accuracy, and data privacy requirements. For data that cannot leave your servers, we deploy open-source models on your own infrastructure. We are model-agnostic — we recommend what fits your constraints.
Generative AI development means building a new AI product or AI-native feature from scratch — designing the architecture, training the data pipeline, and building the user-facing product. AI integration means adding AI capability (an API call, a model endpoint) to software you already have. Most buyers need one of the two. If you are unsure which fits your situation, see our generative AI integration services page.
Look for three things: named client proof with quantified outcomes (not just logos), transparent cost ranges and delivery timelines, and a working prototype before full commitment. Any company that cannot answer 'what will this cost and when will it be done' before signing is a risk. We publish our pricing tiers, quote fixed fees for scoped projects, and build a prototype in 2–4 weeks so you can validate the approach before committing to the full build.
Yes, for well-scoped projects. We give fixed-fee estimates based on a discovery call and technical scoping session. You receive a written quote with milestone dates and deliverables before we start. For exploratory or research-heavy builds where requirements evolve, we work on a time-and-materials basis — and we tell you upfront which model fits your project.
You own everything: the application code, the fine-tuned model weights, the training data pipelines, and the deployment infrastructure. We do not retain IP, use proprietary frameworks that lock you in, or create dependency on us. When the project ends, the code and models are yours to run, modify, or hand to another team.




 Canada
Canada